Redken Colour Fusion Chart
Redken Colour Fusion Chart - Users prefer this for two reasons: The restart block can only be defined at the group level and will be inherited by all tasks. The restart block attempt=0 only prevent an existing allocation from restarting, but a new allocation still kicks in when the existing one fails. In nomad, whenever a task within a job fails or stops, nomad will automatically try to start the task by either restarting the existing allocation or rescheduling an new allocation on another node. Just sharing what i observe: The job restart command is used to restart or reschedule allocations for a particular running job. The reschedule can be defined at the job level and will be inherited by all groups within. Restarting the job calls the restart allocation api endpoint to restart the tasks inside. With the following restart block, a failing task will restart 3 times with 15 seconds between attempts, and then wait 10 minutes before attempting another 3 attempts. In this first post, we'll look at how nomad automates the restart of failed and unresponsive tasks as well as reschedule of repeatedly failing tasks to other nodes. The manual deployment system, prior to nomad, is to start a tmux session on a server and run while :; Users prefer this for two reasons: The job restart command is used to restart or reschedule allocations for a particular running job. This command accepts a single allocation id and a task name. In this first post, we'll look at how nomad automates the restart of failed and unresponsive tasks as well as reschedule of repeatedly failing tasks to other nodes. The restart block can only be defined at the group level and will be inherited by all tasks. The restart block attempt=0 only prevent an existing allocation from restarting, but a new allocation still kicks in when the existing one fails. Just sharing what i observe: In nomad, whenever a task within a job fails or stops, nomad will automatically try to start the task by either restarting the existing allocation or rescheduling an new allocation on another node. The reschedule can be defined at the job level and will be inherited by all groups within. Users prefer this for two reasons: The restart block attempt=0 only prevent an existing allocation from restarting, but a new allocation still kicks in when the existing one fails. In nomad, whenever a task within a job fails or stops, nomad will automatically try to start the task by either restarting the existing allocation or rescheduling an new allocation on. Restarting the job calls the restart allocation api endpoint to restart the tasks inside. With the following restart block, a failing task will restart 3 times with 15 seconds between attempts, and then wait 10 minutes before attempting another 3 attempts. The restart block can only be defined at the group level and will be inherited by all tasks. Just. The manual deployment system, prior to nomad, is to start a tmux session on a server and run while :; In nomad, whenever a task within a job fails or stops, nomad will automatically try to start the task by either restarting the existing allocation or rescheduling an new allocation on another node. The restart block attempt=0 only prevent an. This command accepts a single allocation id and a task name. The restart block can only be defined at the group level and will be inherited by all tasks. Users prefer this for two reasons: The reschedule can be defined at the job level and will be inherited by all groups within. In this first post, we'll look at how. Restarting the job calls the restart allocation api endpoint to restart the tasks inside. In nomad, whenever a task within a job fails or stops, nomad will automatically try to start the task by either restarting the existing allocation or rescheduling an new allocation on another node. The job restart command is used to restart or reschedule allocations for a. With the following restart block, a failing task will restart 3 times with 15 seconds between attempts, and then wait 10 minutes before attempting another 3 attempts. In nomad, whenever a task within a job fails or stops, nomad will automatically try to start the task by either restarting the existing allocation or rescheduling an new allocation on another node.. This command accepts a single allocation id and a task name. In nomad, whenever a task within a job fails or stops, nomad will automatically try to start the task by either restarting the existing allocation or rescheduling an new allocation on another node. The restart block attempt=0 only prevent an existing allocation from restarting, but a new allocation still. In nomad, whenever a task within a job fails or stops, nomad will automatically try to start the task by either restarting the existing allocation or rescheduling an new allocation on another node. Just sharing what i observe: This command accepts a single allocation id and a task name. Restarting the job calls the restart allocation api endpoint to restart. The alloc restart command allows a user to perform an in place restart of an an entire allocation or individual task. The job restart command is used to restart or reschedule allocations for a particular running job. Restarting the job calls the restart allocation api endpoint to restart the tasks inside. The manual deployment system, prior to nomad, is to. The restart block can only be defined at the group level and will be inherited by all tasks. The job restart command is used to restart or reschedule allocations for a particular running job. With the following restart block, a failing task will restart 3 times with 15 seconds between attempts, and then wait 10 minutes before attempting another 3. The restart block can only be defined at the group level and will be inherited by all tasks. Users prefer this for two reasons: With the following restart block, a failing task will restart 3 times with 15 seconds between attempts, and then wait 10 minutes before attempting another 3 attempts. This command accepts a single allocation id and a task name. The restart block attempt=0 only prevent an existing allocation from restarting, but a new allocation still kicks in when the existing one fails. The reschedule can be defined at the job level and will be inherited by all groups within. The manual deployment system, prior to nomad, is to start a tmux session on a server and run while :; Restarting the job calls the restart allocation api endpoint to restart the tasks inside. The alloc restart command allows a user to perform an in place restart of an an entire allocation or individual task. In nomad, whenever a task within a job fails or stops, nomad will automatically try to start the task by either restarting the existing allocation or rescheduling an new allocation on another node.
REDKEN Color Fusion Chart

Redken Color Fusion Chart 2024 Ericka Stephi

redken fusion color chart Redken color chart fusion hair shades eq chromatics charts google gels

redken cover fusion chart Pogot Redken hair color, Hair color chart, Redken color

Redken Color Fusion Chart
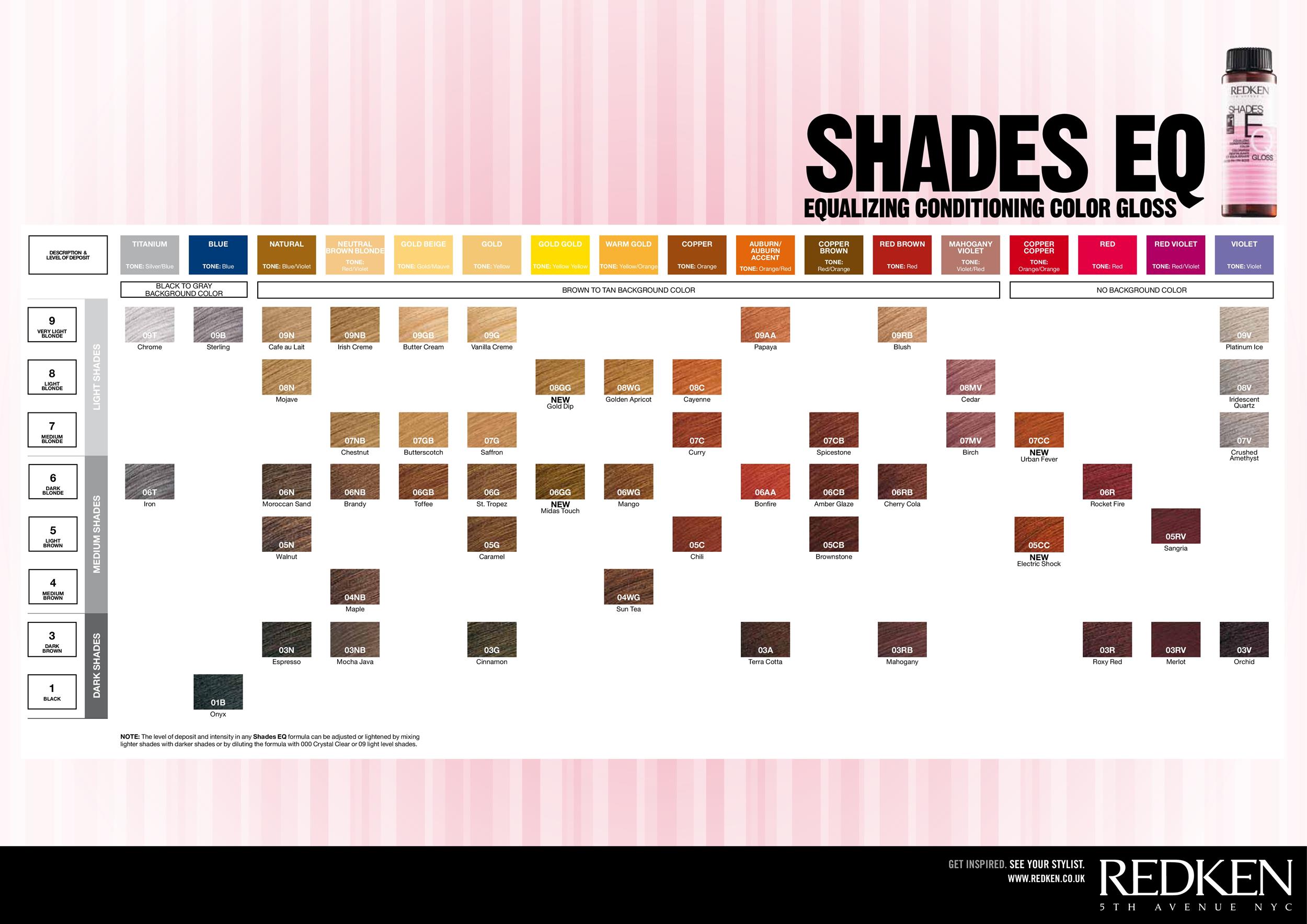
26 Redken Shades EQ Color Charts ᐅ TemplateLab

Redken Color Fusion Chart

Redken Color Fusion Chart Explained

Redken Color Fusion Chart

Redken Color Fusion Color Chart Redken hair color, Redken chromatics color chart, Redken hair
In This First Post, We'll Look At How Nomad Automates The Restart Of Failed And Unresponsive Tasks As Well As Reschedule Of Repeatedly Failing Tasks To Other Nodes.
The Job Restart Command Is Used To Restart Or Reschedule Allocations For A Particular Running Job.
Just Sharing What I Observe:
Related Post: